It's always DNS, How could the AWS DNS Outage be Avoided

"It's always DNS" the phrase that comes up from sysadmin and DevOps alike.
And there are reasons for this common saying, according to The Uptime Institute's 2022 Outage Analysis Report the most common reasons behind a network-related outage are a tie between configuration/change management errors and a third-party network provider failure. DNS failures often fall into these categories. A misconfiguration on this service can make services completely unreachable, leading to a major outage.
This was the case of last AWS us-east-1 outage on 20th October . An issue with DNS prevented applications from finding the correct address for AWS's DynamoDB API, a cloud database that stores user information and other critical data. Now this DNS issue happened to an infra giant like AWS and frankly it could happen to any of us, but are there methods to make our system resilient against this?

What is DNS?
First of all some of you might be wondering, what is DNS? Domain Name System is something like the internet's phone book. It translates human readable names such as www.thevenin.io into IP addresses like 172.217.14.196.
When you type a website address into your browser, DNS servers look up the corresponding IP address so your device knows where to send the request. Without DNS, all browsers and systems would have to hardcode numerical IP addresses for every website and service.

How can we make our system resilient against DNS issues?
Can we avoid DNS issues increasing TTL?
Time to Live, or TTL, is the time the record lives inside the DNS cache. In theory if we set a huge TTL the record lives forever so no issues right? We can keep hitting DynamoDB API.
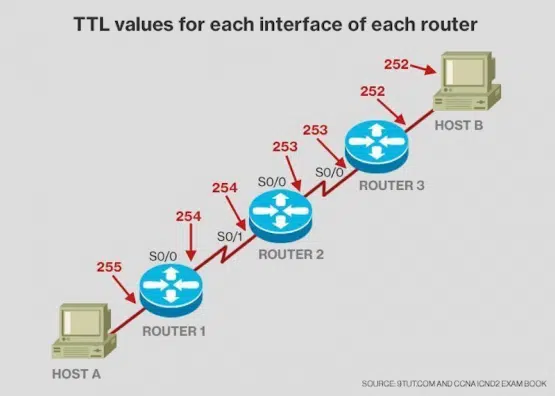
Well wrong, it is a terrible idea. The thing is IPs are meant to change. When we are hitting one API we are usually not hitting one server, but a collection of servers with different IPs. Even if we were to hit only one server it is extremely likely the IP of it will change on rollout, scaling, update, maintenance and many different events that happen in daily operations.
Big TTLs are only used for registries that don't change often, such as nameserver. Nameservers are setup once for a DNS Zone, it is only changed when the zone is migrated from one provider to another (for example AWS Route53 to Cloudflare ).
So we completely discarded increasing TTL, so what else can we do?
Can we be resilient against DNS issues using a DNS Backup Server?
Backup DNS are failover servers for main DNS servers. Usually Cloud Providers like AWS have multiple DNS Servers so their applications can resolve to the requested services. If the main DNS Server goes down you can connect to the Backup one which should have a replica of the same records. Sounds good right? Well it is more complex to setup in practice.
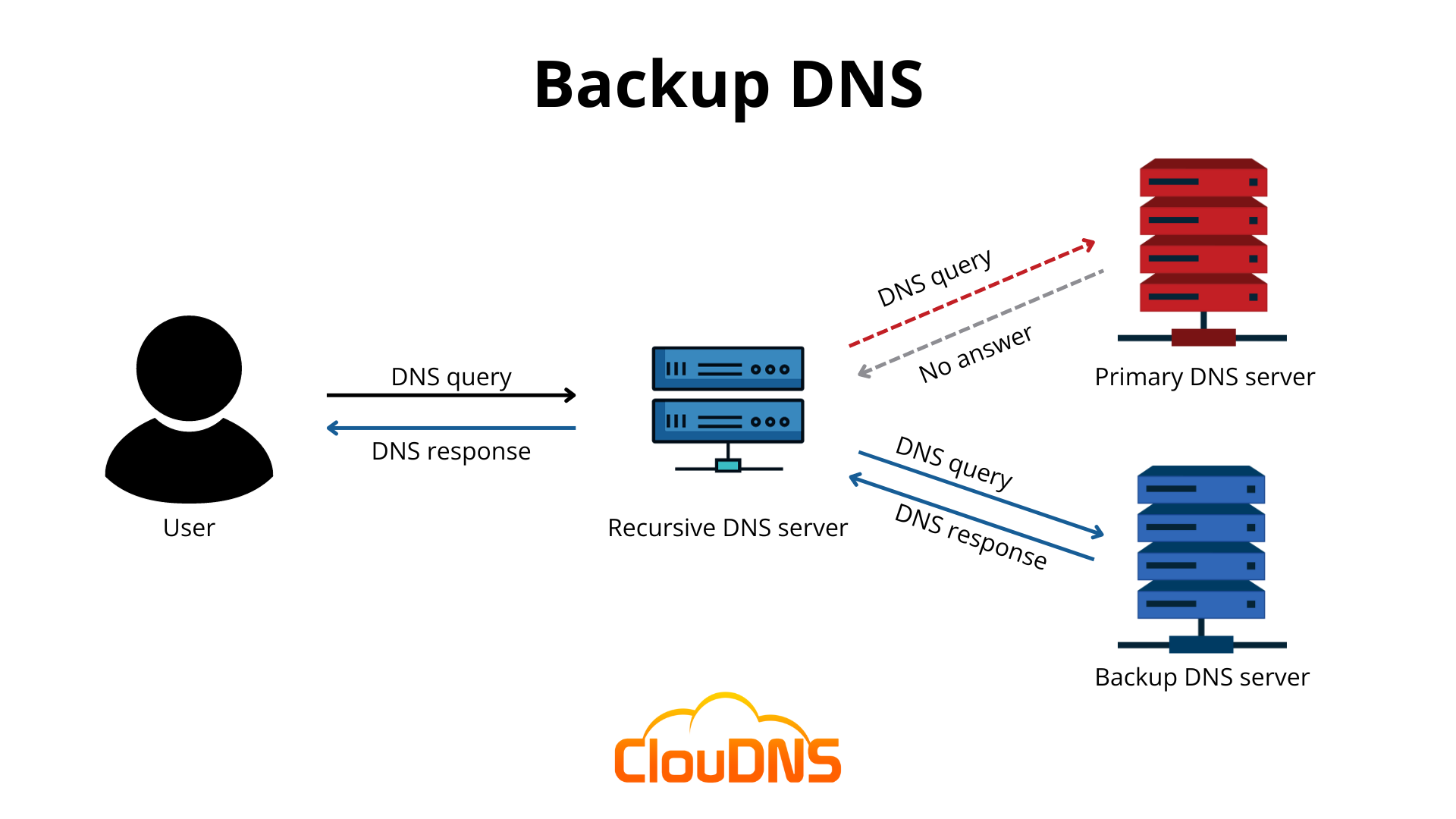
A Backup DNS needs to have records replicated once in a while. This is a periodic load our main DNS has to take which can degrade performance and at the same time the records arrive with latency to the Backup server, so applications might not get the IPs we are expecting. Moreover the same connections issues you are having with reaching your Main DNS Server or Provider could also be affecting the connection to your backup server, leaving you still without DNS.
In this case in particular it wouldn't have been helpful to remediate the AWS outage, since most of the time spent on the outage was on Root Cause Analysis and that usually applies to any incidence in most companies. According to AWS gossip, the Engineering Team spent the entire day hitting their heads until the MVP Engineer James Hamilton showed up. So even if you do the DNS server switch you already had all that outage time realizing it was dns.
NodeLocal DNSCache with serve_stale to be resilient against DNS outages
A NodeLocal functions just like any other DNS cache. Its primary job is to hold onto a DNS record (like the IP address for dynamodb.us-east-1.amazonaws.com) for the duration of its Time-to-Live (TTL).

However the serve_stale CoreDNS option is the one key feature that could have made a difference, depending on its configuration. NodeLocal DNSCache can be set up with a serve_stale option.
Serving Stale data is a RFC pattern to improve DNS resiliency. If this feature is enabled, when the TTL expires and the cache fails to get a new record from the upstream server, it can be instructed to return the old, expired ("stale") record anyway. This allows applications to continue functioning on the last known IP. However rememeber this works while the record is actually valid. If the IP of the DynamoDB changed while the DNS server or resolver was down the applications will have issues reaching the service anyway.
Even if there are risks associated with the IP change this method helps with the retry storm. Once the DNS service started to recover, it was immediately hammered by millions of clients all retrying at once, knocking it back down. A NodeLocal DNSCache helps mitigate this. Instead of 100,000 pods on your nodes all hammering AWS DNS, only the single cache on each node would send a query. This reduces the number of outgoing requests and would have helped the service recover more smoothly.
This method might not be completely fail proof, but helps reduce the damages of the outage and makes your system more resilient.
What actually hapened in AWS DNS Outage
All of the methods above could make some system resilient regarding DNS issues. But in the specific case of the AWS outage new info shows that all DNS records were deleted by an automated system:
"The root cause of this issue was a latent race condition in the DynamoDB DNS management system that resulted in an incorrect empty DNS record for the service’s regional endpoint (dynamodb.us-east-1.amazonaws.com) that the automation failed to repair. " AWS RCA
All registries were empty and the DNS Server was sending an empty response.
How can Kubernetes Operators allow us to not make the same mistakes
A Kubernetes Operator is a specialized, automated administrator running inside a Kubernetes Cluster. Its purpose is to capture the complex, application-specific knowledge of an Operations administrator and run it 24/7, think it like an automated SRE. While Kubernetes is great at managing simple applications, an Operator teaches it how to manage complex resources like DNS.
A widely known Operator we can use in our system to manage DNS is External DNS:
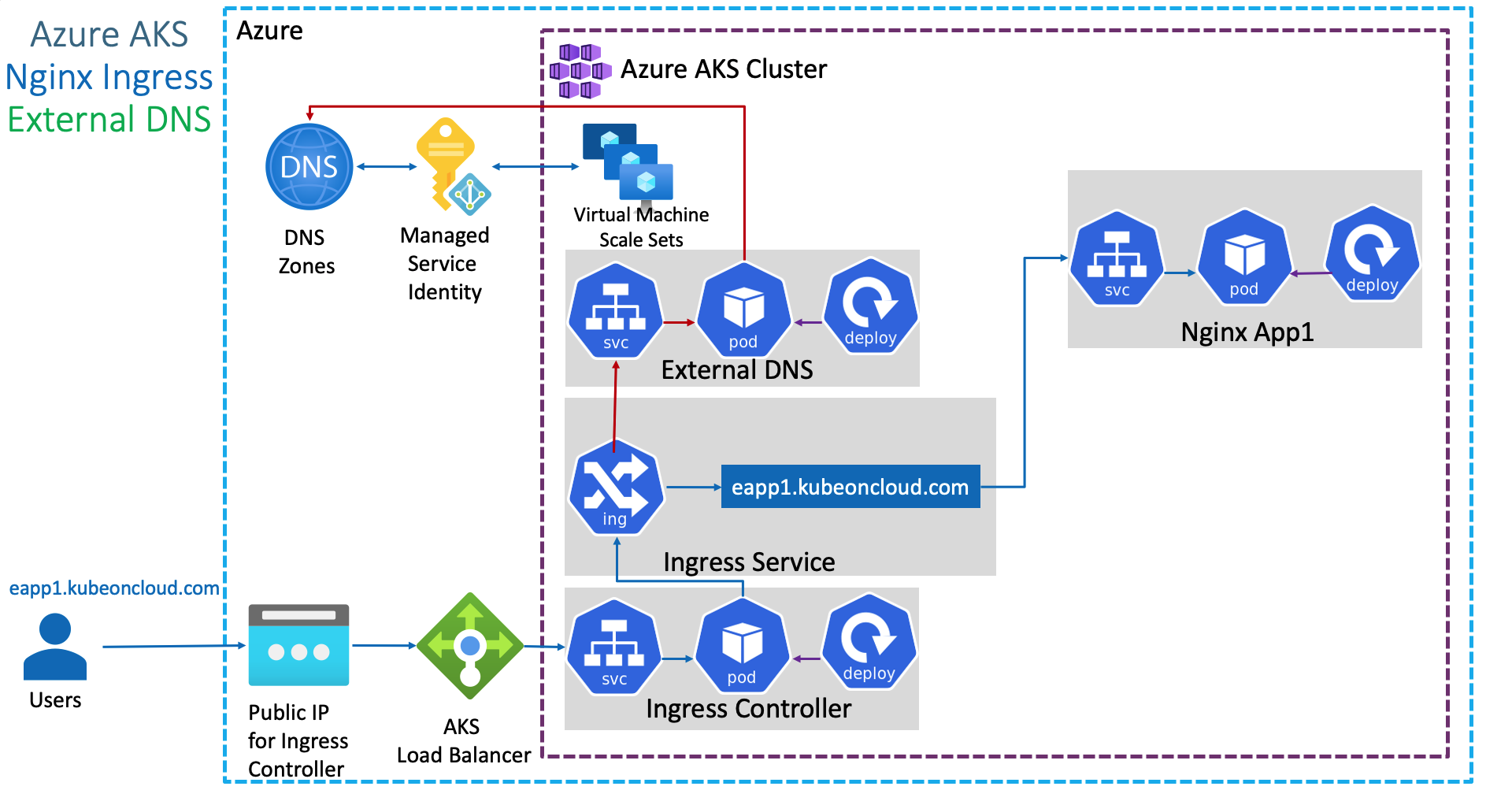
The root cause of the AWS outage wasn't a network failure; it was a bug in their automation. A latent race condition caused their own DNS management system to publish an incorrect, empty DNS record for dynamodb.us-east-1.amazonaws.com. This was a single point of failure.
The Kubernetes Operator model uses a standardized, declarative control loop centered on a single, transactional source of truth (etcd). This design avoids the complex race condition in the AWS DNS System.
The DNS Management System failed because a delayed process (Enactor 1) overwrote new data. In Kubernetes, this is prevented by etcd's atomic "compare-and-swap" mechanism. Every resource has a resourceVersion. If an Operator tries to update a resource using an old version, the API server rejects the write. This natively prevents a stale process from overwriting a newer state.
The entire concept of the DynamoDB DNS Management System, one Enactor applying an old operations plan while another cleans it up is prone to crate concurrency issues. In any system, there should be only one desired state. Kubernetes Operators always try to reconcile toward that one state being based on traditional Control Systems.
Conclusion
It is challenging to have a resilient system, specially if your are AWS. North Virginia us-east-1 was the first region of this cloud provider and is also the default one, making it the most used and the most prone to outages.
However, Operators allow us to get closer to that resiliency. Issues that would arise from custom systems running with scripts are left in the past when you have a controller watching all your resources and reconciling them to the desired state.
Thevenin Platform is entirely built on Kubernetes Operators. We don't run any scripts to deploy apps or resources, everything is reconciled, Try it now at apps.thevenin.io.